本文共 6714 字,大约阅读时间需要 22 分钟。
前几天在云栖社区上写了一篇普惠性的文章,很粗偏向数据架构层面。具体可以进入:,但是在具体实操中肯定不会那么一帆风顺。为了避免大家走弯路特意先写了一篇架构篇,以免大家后续发现不适用而更改或优化工作。
本文偏向与实操层面的为大家介绍,如何基于阿里云数加StreamCompute、DataV快速构建网站日志实时分析。
【什么场景适合用流计算】
流计算提供了针对流式数据实时分析的一站式工具链,对于大量流式数据存在实时分析、计算、处理的逻辑可以考虑通过流计算该任务。举例如下:
1. 针对实时营销活动,需要实时获取活动流量数据分析以了解活动的营销情况,此时可以上流计算。
2. 针对物联网设备监控,需要实时获取设备数据进行实时灾难监控,此时可以上流计算。
3. 对于手机APP数据实时分析,需要实时了解手机设备的各类指标情况,此时可以上流计算
【使用前须知】
为保障本教程的顺利的进行,须知晓如下使用前提:
- 具备阿里云账号(淘宝及1688帐号可直接使用会员名登录);
- 下载并安装Logstash的DataHub Output插件。
- 开通//或RDS/产品;
【实现的业务场景】
数据来源于某网站上的HTTP访问日志数据,基于这份网站日志来实现如下分析需求:
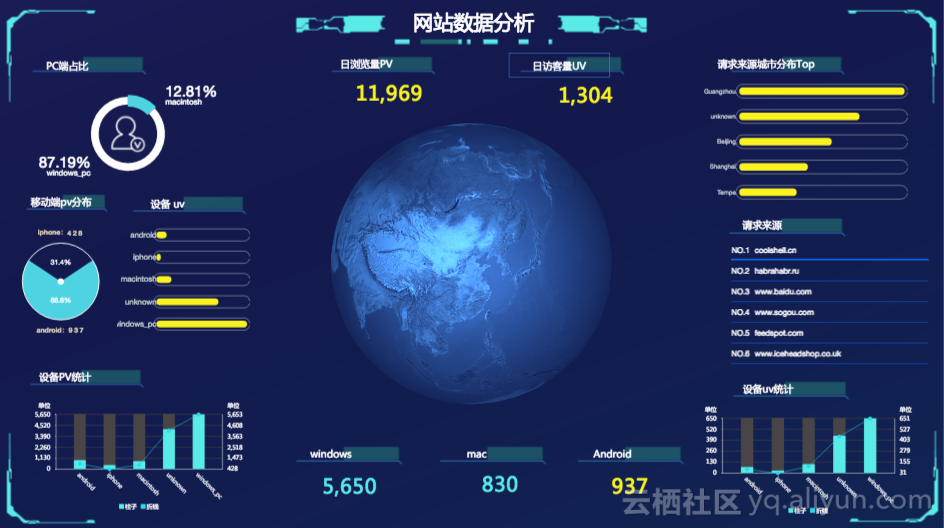
- 实时统计并展现网站的PV和UV,并能够按照用户的终端类型(如Android、iPad、iPhone、PC等)分别统计。
- 实时统计并展现网站的流量来源。
- 从IP中解析出region或者经纬度在地图上进行展示。
【说明】浏览次数(PV)和独立访客(UV)是衡量网站流量的两项最基本指标。用户每打开一个网站页面,记录一个PV,多次打开同一页面PV 累计多次。独立访客是指一天内,访问网站的不重复用户数,一天内同一访客多次访问网站只计算1 次。Referer 可以分析网站访问来源,它是网站广告投放评估的重要指标,还可以用于分析用户偏好等。
【操作流程概述】
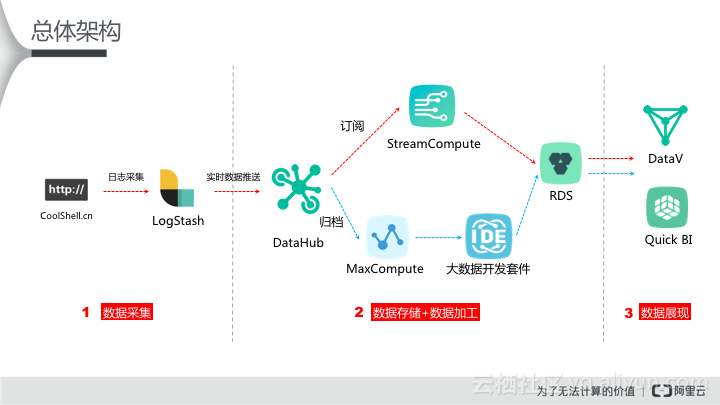
如上图所示,红色箭线部分为流式数据处理部分,主要拆解如下:
l 配置Logstash,将网站产生的日志实时采集至DataHub。
l 申请开通DataHub,创建项目Project及Topic(DataHub服务订阅和发布的最小单位)。
l 开通StreamCompute,创建项目Project及注册数据输入源(DataHub)和输出源(RDS),并创建流任务(Stream SQL任务)。
l 上一步骤中关于输出源RDS的配置,需要事先购买RDS for Mysql资源。
l 申请开通DataV,新建RDS数据源并创建DataV项目进入大屏制作。
【数据结构设计】
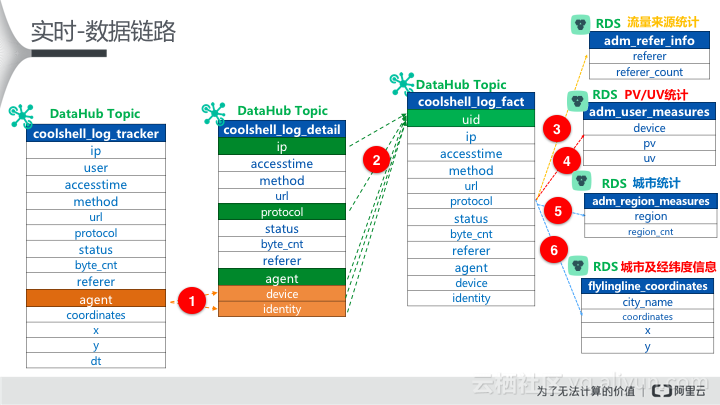
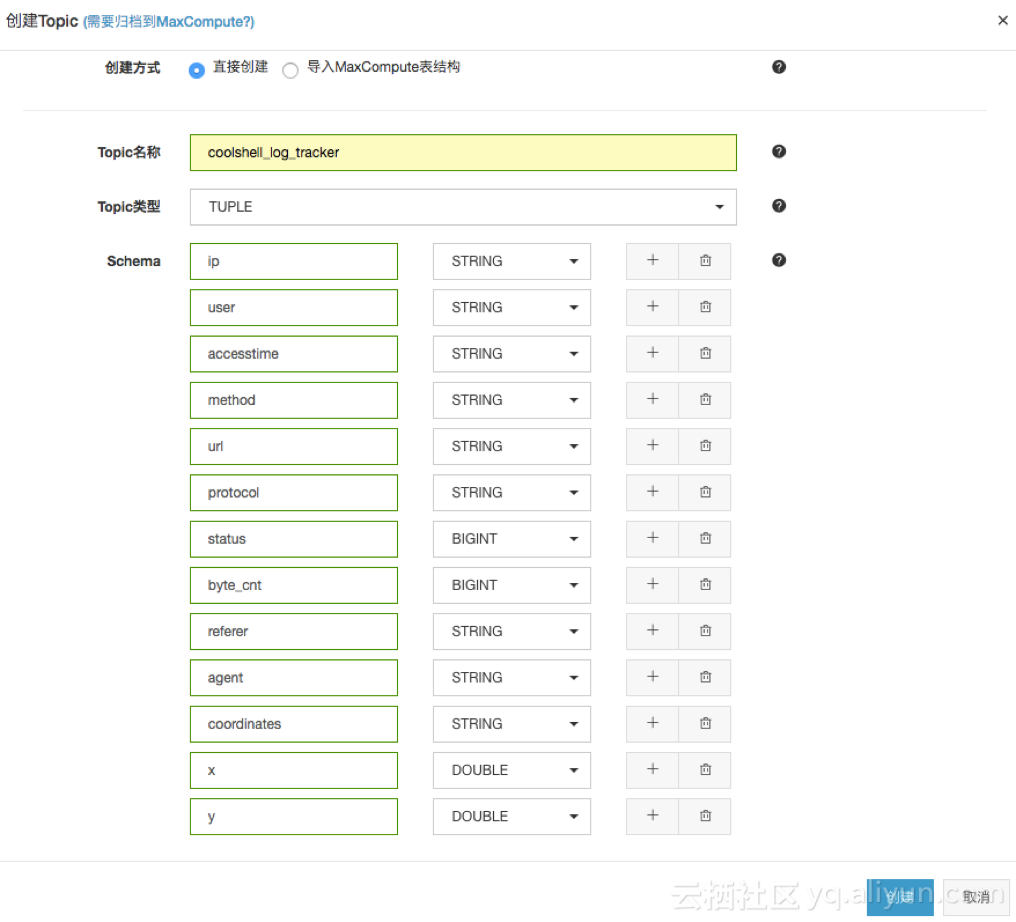
- DataHub Topic: 分别创建Topic为:coolshell_log_tracker、coolshell_log_detail、coolshell_log_fact。
- RDS:分别创建Table为: adm_refer_info、 adm_user_measures、 flyingline_coordinates ã
安装与配置
配置前须知
阿里云流计算为了方便用户将更多数据采集进入DataHub,提供了针对Logstash的DataHub Output插件。
Logstash安装要求JRE 7版本及以上,否则部分工具无法使用。
操作步骤
步骤1 点击下载Logstash 2.4.1,。
步骤2 通过如下命令解压即可使用:
$ tar -xzvf logstash-2.4.1.tar.gz
$ cd logstash-2.4.1
步骤3 下载插件并使用如下命令进行安装:
$ {LOG_STASH_HOME}/bin/plugin install --local logstash-output-datahub-1.0.0.gem
步骤4 下载GeoIP解析IP数据库到本地。
wget http://geolite.maxmind.com/download/geoip/database/GeoLiteCity.dat.gz
步骤5 解压到当前路径并移动到Logstash具体路径下。
gzip -d GeoLiteCity.dat.gzmv GeoLiteCity.dat /etc/logstash/.
步骤6 配置Logstash任务.conf,示例如下:
input { file { path => "/Users/yangyi/logstash-2.4.1/sample/coolshell_log.log" start_position => "beginning" }} filter{ grok { match => { "message" => "(? [^ ]*) - (? [- ]*) \[(? [^\])*]\] \"(? \S+)(?: +(? [^\"]*?)(?: +\S*)?)?(?: +(? [^\"]*))\" (? [^ ]*) (? [^ ]*) \"(? [^\"]*)\" \"(? [^\"]*)\"" }} geoip { source => "ip" fields => ["city_name","latitude", "longitude"] target => "geoip" database => "/Users/yangyi/logstash-2.4.1/bin/GeoLiteCity.dat" add_field => [ "[geoip][coordinates]", "%{[geoip][longitude]}" ] add_field => [ "[geoip][coordinates]", "%{[geoip][latitude]}" ] } mutate { add_field=>{"region" => "%{[geoip][city_name]}"} add_field=>{"coordinates" => "%{[geoip][coordinates]}"} add_field=>{"x" => "%{[geoip][longitude]}"} add_field=>{"y" => "%{[geoip][latitude]}"} convert => [ "x", "float" ] convert => [ "y", "float" ] #convert => [ "coordinates", "float" ] }ruby{ code => " md = event.get('accesstime') event.set('dt',DateTime.strptime(md,'%d/%b/%Y:%H:%M:%S').strftime('%Y%m%d')) " }} output { datahub { access_id => "输入您的access_id" access_key => "输入您的access_key" endpoint => "需要根据自己的网络情况输入对应的endpoint" project_name => "输入您的DataHub Project名称" topic_name => "输入您对应的DataHub Topic" #shard_id => "0" #shard_keys => ["thread_id"] dirty_data_continue => true dirty_data_file => "/Users/yangyi/logstash-2.4.1/sample/dirty.data" dirty_data_file_max_size => 1000 }} 配置文件为coolshell_log.conf。具体DataHub Topic信息可详见 数据存储 章节。
步骤7 启动任务示例如下:
bin/logstash -f sample/coolshell_log.conf
【数据表创建】
附RDS创建表DDL:
---创建adm_refer_info--- CREATE TABLE IF NOT EXISTS adm_refer_info(referer VARCHAR(32) PRIMARY KEY, referer_count BIGINT); --创建adm_user_measures-- CREATE TABLE IF NOT EXISTS adm_user_measures(device VARCHAR(32) PRIMARY KEY, pv BIGINT,uv BIGINT); --创建adm_region_measures --CREATE TABLE `adm_region_measures` ( `region` varchar(32) NOT NULL, `region_cnt` bigint(20) DEFAULT NULL, PRIMARY KEY (`region`)) --创建adm_region_measures --CREATE TABLE `adm_region_measures` ( `region` varchar(32) NOT NULL, `region_cnt` bigint(20) DEFAULT NULL, PRIMARY KEY (`region`)) --创建flyingline_coordinates --CREATE TABLE `flyingline_coordinates` ( `city_name` varchar(32) DEFAULT NULL, `coordinates` varchar(50) DEFAULT NULL, `x` double DEFAULT NULL, `y` double DEFAULT NULL)
【流式数据处理】
注册数据存储包括DataHub和RDS:
按照数据链路图中来编写处理逻辑(附核心代码):
【处理逻辑1】
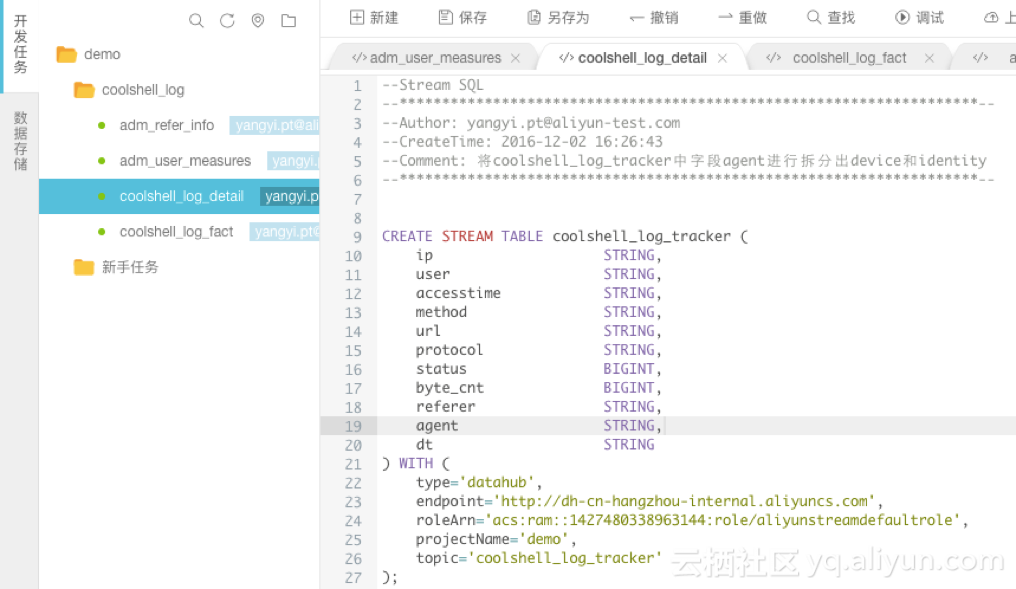
INSERT INTO coolshell_log_detail SELECT ip, accesstime, method, url, protocol, status, byte_cnt, regexp_extract(referer, '^[^/]+://([^/]+){1}') as referer, agent, CASE WHEN TOLOWER(agent) RLIKE 'android' THEN 'android' WHEN TOLOWER(agent) RLIKE 'iphone' THEN 'iphone' WHEN TOLOWER(agent) RLIKE 'ipad' THEN 'ipad' WHEN TOLOWER(agent) RLIKE 'macintosh' THEN 'macintosh' WHEN TOLOWER(agent) RLIKE 'windows phone' THEN 'windows_phone' WHEN TOLOWER(agent) RLIKE 'windows' THEN 'windows_pc' ELSE 'unknown' END AS device, CASE WHEN TOLOWER(agent) RLIKE '(bot|spider|crawler|slurp)' THEN 'crawler' WHEN TOLOWER(agent) RLIKE 'feed' OR url RLIKE 'feed' THEN 'feed' WHEN TOLOWER(agent) NOT RLIKE '(bot|spider|crawler|feed|slurp)' AND agent RLIKE '^[Mozilla|Opera]' AND url NOT RLIKE 'feed' THEN 'user' ELSE 'unknown' END AS identity FROM coolshell_log_tracker WHERE url NOT LIKE '^[/]+wp-'; 【处理逻辑2】
INSERT INTO coolshell_log_fact select md5(concat(ip, device, protocol, identity, agent)),--根据ip、device、protocol、identity和agent字段可以唯一确定uid ip, accesstime, method, url, protocol, status, byte_cnt, referer, agent, device, identity FROM coolshell_log_detail;【处理逻辑3、4、5、6】
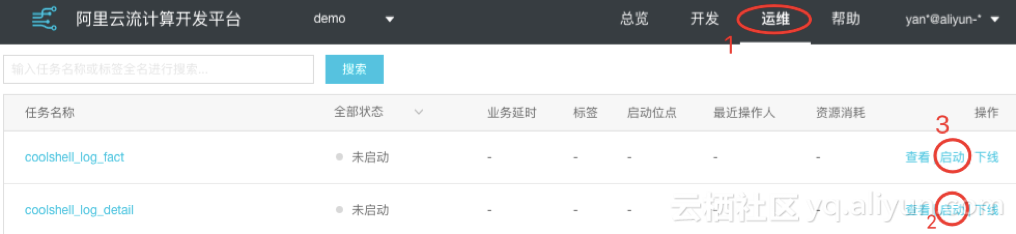
---adm_refer_info中的处理逻辑---REPLACE INTO adm_refer_info SELECT referer,COUNT(referer) as referer_countFROM coolshell_log_factWHERE LENGTHqi(referer) > 1GROUP BY referer;--adm_user_measures中的处理逻辑---REPLACE INTO adm_user_measures SELECT device, COUNT(uid) as pv, COUNT(distinct uid) as uv FROM coolshell_log_fact GROUP BY device;附录:adm_region_measures和flyingline_coordinates处理逻辑REPLACE INTO adm_region_measures SELECT CASE WHEN region='%{[geoip][city_name]}' THEN 'unknown' WHEN region!='%{[geoip][city_name]}' THEN region END AS region,count(region) FROM coolshell_log_tracker_bakGROUP BY region;INSERT INTO flyingline_coordinatesSELECT CASE WHEN region='%{[geoip][city_name]}' THEN 'unknown' WHEN region!='%{[geoip][city_name]}' THEN region END AS region, coordinates,x,y FROM coolshell_log_tracker_bak where coordinates is NOT NULL; 【上线Stream SQL】 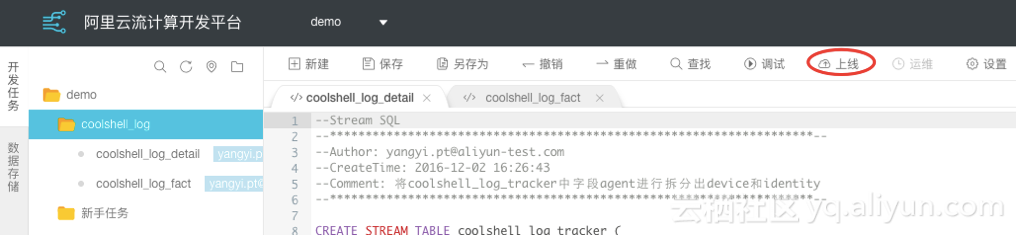

转载地址:http://yvszx.baihongyu.com/